
Table of contents
Ungefähr ein Drittel der werktäglichen Wege der Bevölkerung sind Wege zum oder vom Arbeitsplatz. Daher ist die Information, wie viele Menschen wo in einer Region arbeiten, eine wichtige Grundlage für ein Verkehrsmodell und damit für die Verkehrsplanung einer Region.
Herkömmliche Methoden wie z.B. die Verwendung von verfügbaren Daten (Bundesagentur für Arbeit, Handwerkskammer, IHK), manuelle Recherche bzw. Erhebung der räumlichen Verteilung der Arbeitsplätze sind oft zu ungenau, bzw. langsam und ineffizient, da es Monate dauert, die notwendigen Informationen zu sammeln und als Datenbasis bereitzustellen. Auch sind diese Methoden anfällig für Fehler, was am Ende die Qualität eines Verkehrsmodells bzgl. der Übereinstimmung mit der Realität beeinträchtigen kann.
Ein Problem ist auch die unvollständige amtliche Erfassung der Beschäftigen. In vielen Datensätzen werden beispielsweise nur sozialversicherte Beschäftigte erfasst. Wichtige Gruppen wie Beamt*innen oder Selbstständige werden nicht berücksichtigt. Darüber hinaus verknüpfen einige Datenquellen alle Beschäftigten eines Betriebs mit einer einzigen Adresse, wodurch das sogenannte „Headquarter-Problem“ entsteht (z.B. alle Mitarbeiter eines Discounters werden dem Firmensitz zugeordnet). In Wirklichkeit arbeiten oft viele Mitarbeiter in den einzelnen Standorten eines Betriebs, was zu einer fehlerhaften Verteilung der Arbeitsplätze im Modellgebiet führt. Die manuelle Aufbereitung genauer Daten erfordert zudem lokale Kenntnisse, um die Beschäftigten korrekt auf die Büro- und Gewerbegebiete einer Stadt zu verteilen. Als Teil unserer Software PTV Model2Go haben wir ein KI-Tool entwickelt und trainiert, das einen schnelleren, skalierbaren und präzisen Ansatz zur Schätzung von Beschäftigtendaten für die Verkehrsplanung bzw. Verkehrsmodelle bietet.
So haben wir das KI-Tool entwickelt
Unser KI-Tool wurde mit Daten des Bundesamts für Statistik der Schweiz trainiert. Aktuell nutzt es das Gelernte, um die Zahl der Beschäftigten für Deutschland zu schätzen. Auch wenn sich die beiden Länder wirtschaftlich unterscheiden, haben Gebäude mit ähnlicher Grundfläche, Höhe und Flächennutzung in der Regel eine vergleichbare Anzahl von Mitarbeitenden. Wir nutzen einen zweistufigen Ansatz des maschinellen Lernens als Vorhersagemodell.
Zunächst bestimmt ein Klassifikationsalgorithmus für jedes Gebäude einen Typ anhand von Attributen wie Grundfläche, Fläche, Höhe und Flächennutzung. Anschließend wird mit Hilfe einer Regression die Anzahl der Beschäftigten in einem 100m x 100m-Raster anhand dieser Gebäudetypen sowie zusätzlicher Attribute geschätzt.
Das Tool ermittelt die Zahl der Arbeitnehmer*innen sowohl auf 100m-Rastern als auch für jedes einzelne Gebäude. Dies liefert hochauflösende Daten, die Verkehrsmodelle verbessern können. Die Berechnungen auf Gebäudeebene eigenen sich sowohl für traditionelle als auch für detailliertere Verkehrsnachfragemodelle wie mikroskopische aktivitätsbasierte Modelle (ABMs).
Datenquellen
Die neue KI-Lösung wird auf mehreren öffentlich verfügbaren Datensätzen trainiert. Zu den wichtigsten Datenquellen gehören:
- OpenStreetMap (OSM): Bietet detaillierte Gebäudegrundrisse, Landnutzung und Points-of-Interest.
- Overture Maps: Bietet Informationen über Landnutzung und Points-of-Interest.
- Corine Land Cover: Hilft bei der Klassifizierung von Landnutzung und Flächendeckung.
- Zensusdaten: Liefert Informationen zur Bevölkerung ( in Deutschland, Daten des Zensus 2022)
- 3D-Gebäudemodelle: Liefert die Höheninformationen der Gebäude.
- Daten des Schweizerisches Bundesamt für Statistik: Gebäudetypinformationen und Beschäftigtendaten
Inputdaten werden benötigt, um Prognosen für ein Zielland (zunächst für Deutschland) zu berechnen. Wir verwenden dafür ähnliche Informationen mit genauso hoher Qualität wie für die Kalibrierung des Modells mit Schweizer Daten. Einige Datensätze stammen aus den gleichen Quellen, andere wiederum sind länderspezifisch.
Vorteile der KI-gestützten Schätzung von Beschäftigtenzahlen für Verkehrsmodelle
Geschwindigkeit
Herkömmliche Methoden zur Erfassung von Beschäftigtendaten sind langsam und erfordern oft monatelange manuelle Arbeit und lokale Kenntnisse. Unser KI-basierter Ansatz beschleunigt diesen Prozess, indem er die Schätzung automatisiert. So können Verkehrsmodelle schneller aufgesetzt werden. Nutzende können sich auf andere wichtige Projektaufgaben wie etwa die Modellkalibrierung und -validierung konzentrieren.
Lösung des Headquarter-Problems
Der zweistufige Ansatz des KI-Tools trägt dazu bei, das „Headquarters-Problem“ zu lösen, bei dem alle Beschäftigten einer Firma bzw. Betriebs mit einer einzigen Adresse verknüpft werden. Dies tritt in vielen offiziellen Datenquellen auf. Durch die Vorhersage von Gebäudetypen und die Schätzung der Zahlen der Arbeitnehmer*innen auf der Grundlage individueller Gebäudeattribute verteilt das Tool die Beschäftigten genauer über das Modellgebiet und verhindert eine unrealistische Häufung an einem Standort.
Konsistente Qualität
Die Qualität der Daten, die in der KI für die Berechnungen verwendet werden, ist im gesamten Zielland einheitlich. Nutzende erhalten also eine einheitliche Qualität der Schätzung an Beschäftigtendaten für jedes Gebiet eines Landes.
Qualitätssicherung
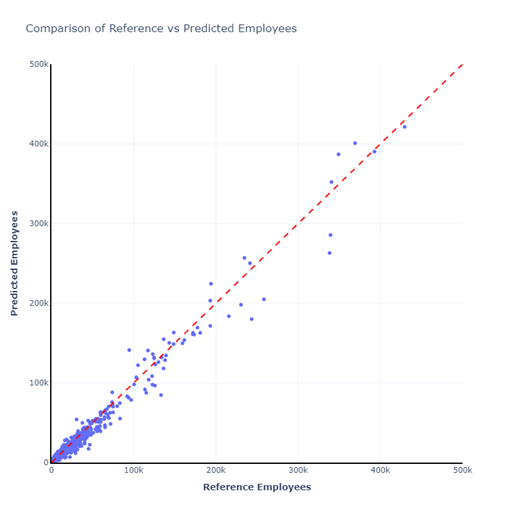
In der Trainingsphase teilen wir die Daten in der Regel in einen Trainings- und einen Testdatensatz auf. Ziel ist es, die Qualität der Schätzungen unserer KI mit dem Testdatensatz zu überprüfen.
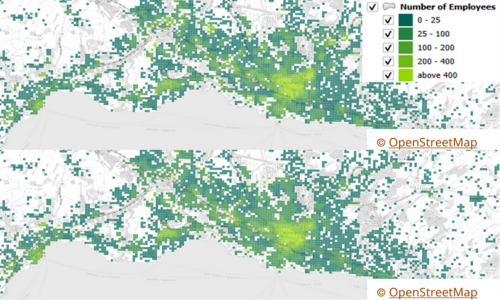
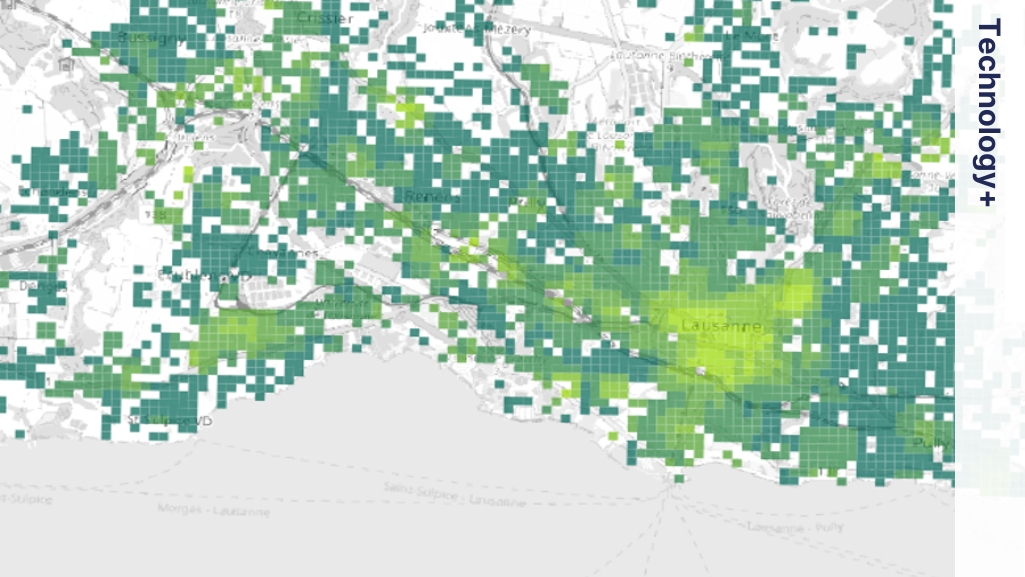
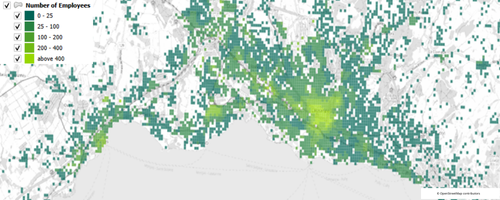
Es ist jedoch nicht einfach, die Raster zweier Datensätze zu vergleichen, um die Qualität der Daten zu überprüfen. Oftmals überschneiden sich Gebäude mit mehreren Rasterzellen, so dass ein genauer Vergleich nicht möglich ist. Aus diesem Grund haben wir analysiert, wie sich die Unterschiede zwischen den Datensätzen auf ein Verkehrsmodell auswirken. Die ausführliche Analyse ist in einem separaten Validierungsbericht enthalten.
Regional Statistics
Eine weitere Vergleichsquelle für Mitarbeiterzahlen sind Daten von den statistischen Ämtern, die Informationen auf Gemeindeebene in Deutschland bereitstellen (regionalstatistik.de). Die KI-Daten werden auf Gemeindeebene aggregiert, um einen Vergleich zu ermöglichen. Es ist wichtig zu beachten, dass dieser Vergleich die rohen KI-Schätzungen verwendet, bevor sie auf Gemeindeebene skaliert werden.
Für weitere Validierungen, insbesondere Stichprobenvergleiche mit anderen Datenquellen, siehe den Validierungsbericht.
Nutzung der KI-basierten Schätzung
Unsere KI-basierten Beschäftigtenschätzungen sind ein zuverlässiger Ausgangspunkt für Verkehrsmodelle. Nutzende sollten jedoch zusätzlich prüfen, dass die Daten ihren spezifischen Anforderungen entsprechen.
Zunächst sollte der Datensatz auf etwaige Extremwerte geprüft werden. Obwohl das KI-Tool recht genau ist, kann die manuelle Überprüfung dieser Extremwerte dazu beitragen, die Zuverlässigkeit der Daten zu erhöhen.
Bei sehr großen Arbeitgebern, wie zum Beispiel Automobilherstellern, können die Schätzungen der Mitarbeitendenzahlen ungenau sein, da der KI für solche Fälle Trainingsdatensätze fehlen. Nutzende sollten die Beschäftigtenzahlen solcher großen Arbeitgeber recherchieren (Informationen sind meist online verfügbar) und die Schätzungen bei Bedarf manuell anpassen.
Geplante Weiterentwicklung des KI-Tools
Wir erweitern, verfeinern und verbessern unser KI-gestütztes Tool zur Schätzung von Beschäftigtenzahlen kontinuierlich. Zu unseren Hauptschwerpunkten gehören:
Ausdehnung auf weitere Länder
Unser KI-Tool wird aktuell zur Schätzung von Beschäftigtendaten für Deutschland eingesetzt. Geplant ist, es auf weitere europäische Länder mit ähnlichen Flächennutzungs- und Strukturdaten, auszuweiten.
Schätzung anderer struktureller Daten
Über die Beschäftigtenzahlen hinaus, wollen wir das KI-Tool um weitere wichtige Standortdaten für Verkehrsmodelle zu erweitern, wie z.B. Einkaufszentren, Schulen, Freizeit- und Gesundheitseinrichtungen. Ziel ist es, vollständigere Informationen für Verkehrsmodelle bereitzustellen.
Kontinuierliche Verbesserung
Um das Tool noch weiter zu verbessern, sammeln wir ständig weitere offene Daten und aktualisieren unsere Trainingsmodelle. Sobald wir neue Daten erhalten, integrieren wir diese in den Trainingsdatensatz, um die Genauigkeit unserer Vorhersagen zu verbessern.

PTV Model2Go
In nur einer Woche zum Verkehrsmodell Ihrer Stadt. Erfahren Sie mehr über unsere Automatisierungstechnologie.
Entdecken Sie PTV Model2Go
In nur einer Woche zum Verkehrsmodell Ihrer Stadt.
Ähnliche Beiträge


