
Table of contents
Approximately one-third of daily journeys are related to commuting to and from work. Consequently, understanding where people work within a region is a critical foundation for developing transport models and effective transportation planning and decision-making. Traditional methods of collecting and preparing this data such as relying on available data from sources like the Federal Employment Agency, or the Chamber of Industry and Commerce, as well as manual research or surveys of job distribution, are often slow and inefficient. Gathering the necessary information and compiling it into a usable database can take months. Moreover, these methods are prone to errors, which can ultimately compromise the accuracy and reliability of a transport model in reflecting real-world conditions.
One major challenge is incomplete coverage of where employees work. Many datasets only account for socially insured employees, leaving out important groups like civil servants, and the self-employed; or are only collected periodically, such as the Census which can quickly become out of date.
Additionally, some data sources associate all employees of an organization to a single address, resulting in what is known as the “headquarters problem”, where employees are inaccurately inked to the company’s main office. In reality, many employees work at the individual branch locations of the company. This misrepresentation leads to an inaccurate distribution of jobs within the model area
Preparing accurate data also requires local knowledge to correctly distribute employees across office and industrial zones in a city. As part of our software, PTV Model2Go, we developed and trained an AI tool that tackles this challenge providing a faster, more scalable, and accurate approach to estimating employee data for transport models.
How we developed the AI tool
In transport modeling, accurate employee data is crucial, yet collecting it can be time-consuming and inconsistent, especially when official data is incomplete or unavailable. This is where our AI tool comes in. It is trained on high quality data from the Swiss Federal Statistical Office and uses what it has learned to estimate employee numbers in Germany. While the two countries may differ economically, buildings with similar footprints, heights, and land use typically house a comparable number of employees. Thus, by using the Swiss dataset—which includes detailed information on job locations—as a training model, the AI can infer job distributions in other regions where such data is lacking. To achieve this, we use a two-step machine learning approach, with gradient-boosted trees as the prediction model.
First, a classifier predicts building types based on attributes like footprint, area, height, and land use. Then, a regressor estimates the number of employees in 100m x 100m grids using these building types and additional attributes.
The tool estimates employees at 100m grids as well as per each building. This provides high-resolution data that enhances transport models, especially those with larger zones. Furthermore, the building-level estimates make the tool valuable for both traditional models and more detailed ones like activity-based models (ABMs).
Data Sources
The new AI tool is trained on several publicly available datasets. The main data sources include:
- OpenStreetMap (OSM): Provides detailed building footprints, land use and points-of-interest.
- Overture Maps: Offers land use and point-of-interest information.
- Corine Land Cover: Helps classify land use and land cover.
- Census Data: Provides population information.
- 3D Building Models: Provides the height information for the buildings.
- BFS (Swiss Federal Statistical Office): Supplies key building type information and employee data for training the model.
To generate forecasts for a target country (initially Germany), input data is required. We utilize similar high-quality information as was used for calibrating the model with Swiss data. While some datasets originate from the same sources, others are specific to the target country.
Benefits of AI-Based Employee Estimation for Transport Models
Speed
Traditional methods of collecting employee data are slow and often require months of manual work and local knowledge. Our AI-based approach speeds up this process by automating the estimation of employee numbers. This enables transport models to be developed more quickly, allowing users to focus more time on other important project tasks, such as model calibration and validation.
Solving the Headquarter Problem
The AI tool’s two-step approach helps overcome the “headquarter problem” found in many official data sources, where all employees are linked to a single address. By predicting building types and estimating employee numbers based on individual building attributes, the tool distributes employees more accurately across the model area, preventing unrealistic clustering at one location.
Consistent Quality
The quality of input data used in the AI tool for predictions is consistent across the target country, so users can also expect a consistent quality of employee estimates for every area of the country..
Quality Assurance
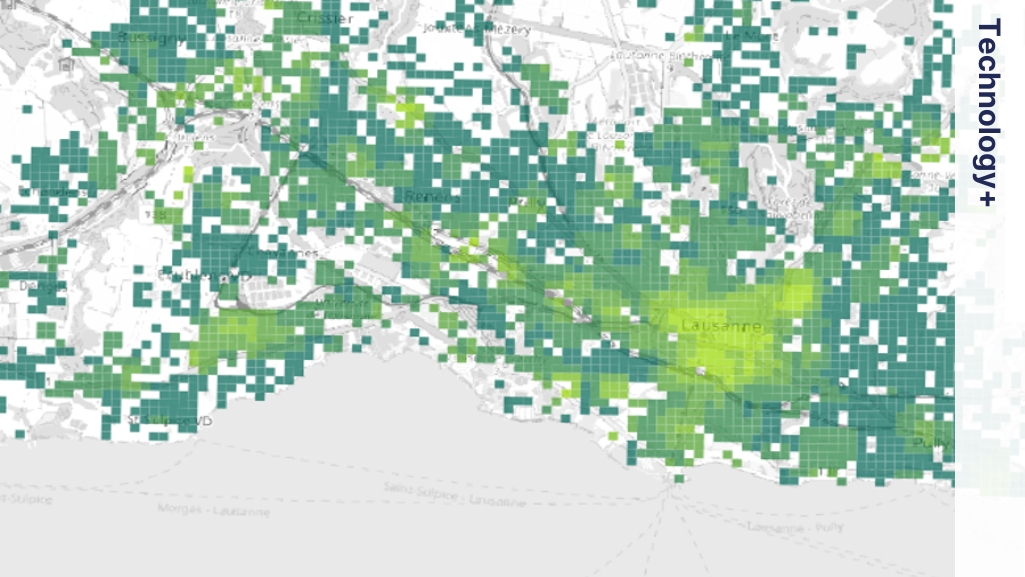
During the model training process, we usually divide the data into training and testing sets. The aim is to check the quality of the estimation from our AI with this test dataset. The figure below shows the grid-level comparison of the test dataset (Official) with AI estimates.
However, it’s not straight-forward to simply compare grid cells from two datasets to check the quality of the data. Many times, buildings overlap multiple grids, and an accurate comparison might not be possible. Therefore, we analyzed the effect of the gap between the official and AI data on a transport model. The detailed in-depth analysis is available in a separate validation report that users can refer to.
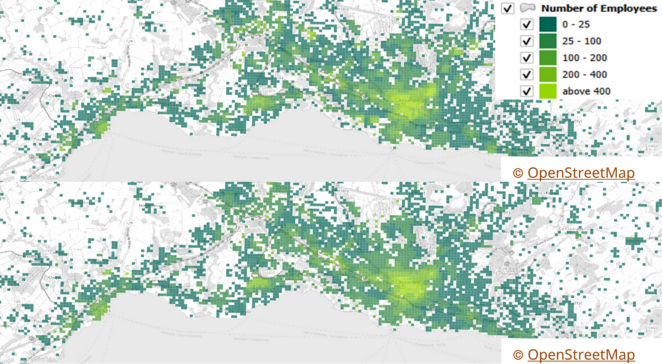
Regional Statistics
Another comparison source for employee numbers is data from the Statistical Offices, which provide information at the community level in Germany (regionalstatistik.de). The AI data is aggregated to the community level for comparison. It’s important to note that this comparison uses the raw AI estimates before scaling at the community level.
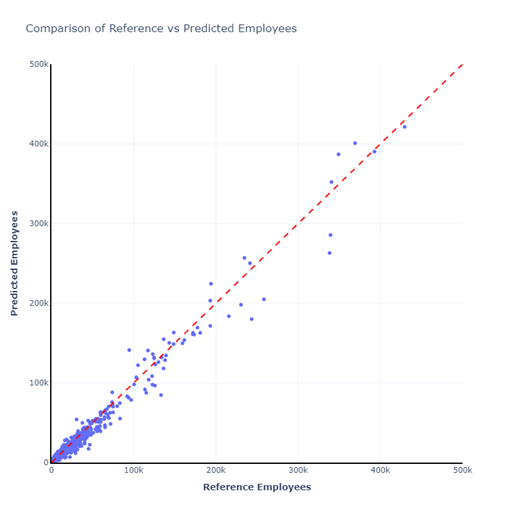
For more validation, especially spot comparisons with other data sources, please refer to the validation report.
Usage of AI-based estimates
While our AI-based employee estimates are a reliable starting point for transport models, users should take a few steps to ensure the data fits their specific needs.
First, it is recommended to check the dataset for any extreme values. Although the AI tool is quite accurate, manually reviewing these extreme values can help confirm the data’s reliability, especially for important use cases.
Additionally, the AI tool may struggle with very large employers such as big car manufacturers. and may not be able to predict employee numbers precisely due to the lack of such cases in the training dataset. We suggest that users research these large employers — information that is often available online — and make manual adjustments to the estimates where necessary.
Next Steps in AI-Based Estimation
We are continuously expanding and refining our AI-based employee estimation tool to further enhance its utility for transport modelling. Our key areas of focus include:
Expanding to Further Countries
Our AI tool is now being used to estimate employee data for Germany. We plan to expand the tool to more European countries with similar land use and structural data. With this step-by-step approach, we ensure high accuracy in specific areas before scaling to larger regions.
Estimating Other Structural Data
Beyond employee numbers, our next goal is to include other important attraction data for transport models, like shopping centers, schools, leisure and healthcare facilities. By adding this additional attraction potential, we aim to provide more complete information for transport models.
Continuous Improvement
To keep the tool accurate and adaptable, we are continuously gathering more open data and updating our training models. As new data comes in, we will integrate it into the training dataset to improve the accuracy of our predictions.

Model. Set. Go
Get a transport model of your city in just a week.
White Paper: Transportation Modeling
How do you create a transportation model? What are the so-called “four steps” of transportation modeling? What is activity- or agent-based modeling? Read this white paper and find the answers to the most important questions.
Related Posts


